引例
数值微分计算梯度,虽然简单,但耗时。误差反向传播法可以高效计算权值参数。
计算图法
可以通过传递”局部计算”来获取最终结果
局部计算指只关心与自己相关的数据。
反向传播即可方便计算出各个导数
反向传播是基于链式法则的:
$$\frac{\delta z}{\delta x} = \frac{\delta z}{\delta t} \times \frac{\delta t}{\delta x}$$
实现
乘法层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
class MulLayer:
def __init__(self):
self.x=None
self.y=None
def forward(self,x,y):
self.x=x
self.y=y
out=x*y
return out
def backward(self,dout):
dx=dout*self.y
dy=dout*self.x
return dx,dy
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
apple = 100
apple_n=2
tax=1.1
mul_apple_layer=MulLayer()
mul_tax_layer=MulLayer()
apple_price = mul_apple_layer.forward(apple,apple_n)
price = mul_tax_layer.forward(apple_price,tax)
print(price)
dprice = 1
dapple_price , dtax = mul_tax_layer.backward(dprice)
dapple , dapple_n = mul_apple_layer.backward(dapple_price)
print(dapple,dapple_n,dtax)
|
220.00000000000003
2.2 110.00000000000001 200
加法层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
class AddLayer:
def __init__(self) -> None:
pass
def forward(self,x,y):
out=x+y
return out
def backward(self,dout):
dx=dout*1
dy=dout*1
return dx,dy
|
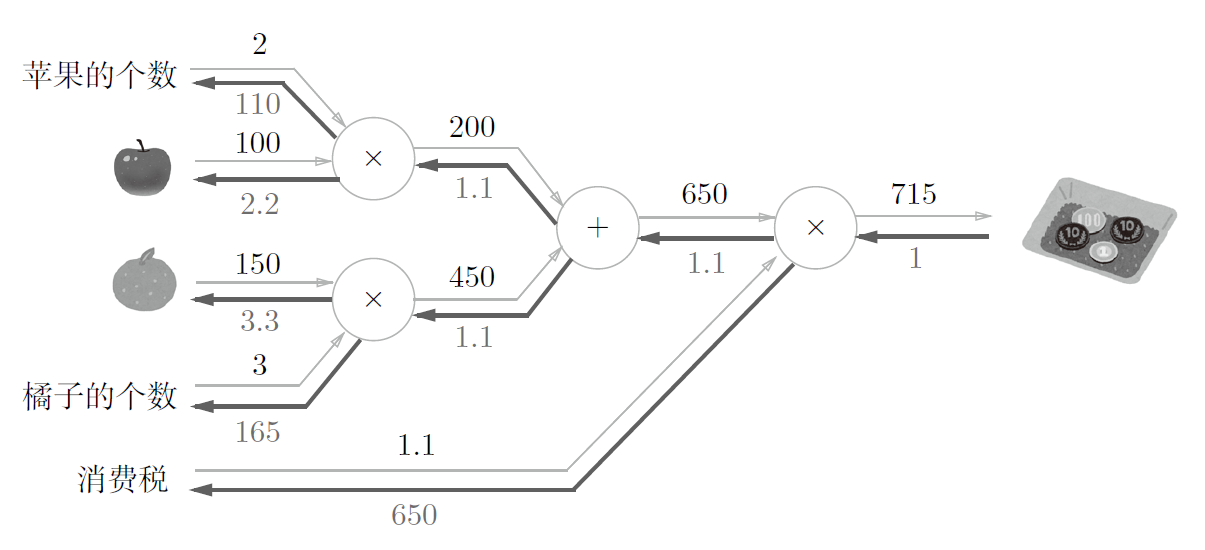
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
apple=100
apple_num=2
orange=150
orange_num=3
tax = 1.1
mul_apple_layer = MulLayer()
mul_orange_layer=MulLayer()
add_fruit_layer = AddLayer()
mul_tax_layer = MulLayer()
apple_price = mul_apple_layer.forward(apple,apple_num)
orange_price = mul_orange_layer.forward(orange,orange_num)
fruit_price = add_fruit_layer.forward(apple_price,orange_price)
price = mul_tax_layer.forward(fruit_price,tax)
dprice = 1
dfruit_price , dtax = mul_tax_layer.backward(dprice)
dapple_price , dorange_price = add_fruit_layer.backward(dfruit_price)
dorange , dorange_num = mul_orange_layer.backward(dorange_price)
dapple , dapple_num = mul_apple_layer.backward(dapple_price)
print(price)
print(dapple_num,dapple,dorange_num,dorange,dtax)
|
715.0000000000001
110.00000000000001 2.2 165.0 3.3000000000000003 650
加入激活函数
1. ReLU[^Rectified Linear Unit]层
ReLU函数导数:
$$ \frac{\delta y}{\delta x} =
\begin{cases}
1, & (x > 0), \
0, & (x \leq 0)
\end{cases}
$$
故,其在反向传播时,若x>0,则输出前一层delta;否则输出0。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
class ReLU:
def __init__(self) -> None:
pass
def forward(self,x):
self.mask = (x<=0)
out=x.copy()
out[self.mask] = 0
return out
def backward(self , dout):
dout[self.mask]=0
dx = dout
return dx
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import numpy as np
x = np.array([[1.0,-0.5],[-2.0,3.0]])
print(x)
mask = (x<=0)
print(mask)
|
[[ 1. -0.5]
[-2. 3. ]]
[[False True]
[ True False]]
Sigmoid 层
函数:
$$ y = \frac{1}{1+e^{-x}}$$
正向传播,从输入x开始,依次进行了
x = x * -1 乘法层
x = exp(-x) 幂次层
x = 1 + x 加法层
y = 1 / x 除法层
逆着逐级求导,可得最终结果为
$$ \frac{\delta L}{\delta y} \times y^2 \exp{-x} = \frac{\delta L}{\delta y} y(1-y) $$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class Sigmoid:
def __init__(self):
self.out=None
def forward(self,x):
out= 1/(1+np.exp(-x))
self.out=out
def backward(self,dout):
dx=dout*(1.0-self.out)*self.out
return dx
|
Affine/Softmax 层
1. Affine层
Affine就是矩阵运算中的乘积运算,也可以理解为仿射变换。
几何中的仿射变换包括一次线性变换和一次平移,对应神经网络的加权运算和加偏置运算。
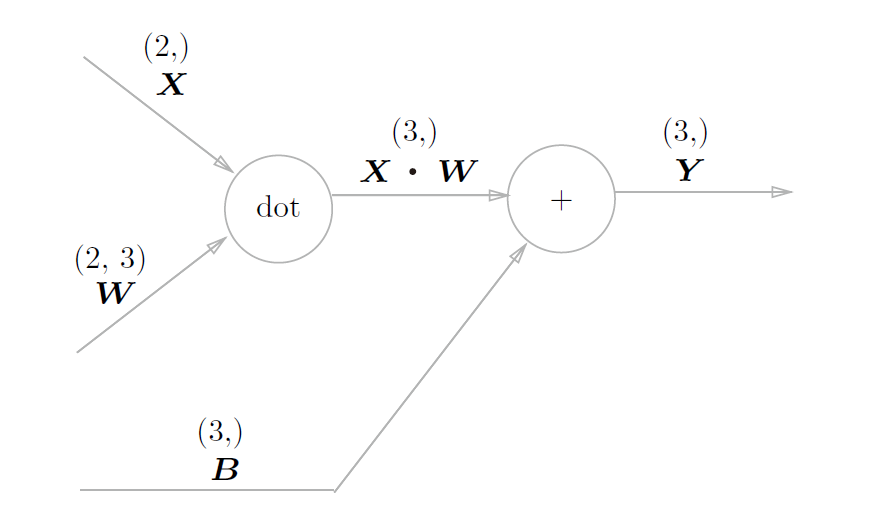
对其求导,可以得到
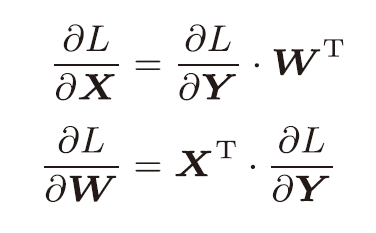
故它的反向传播为:
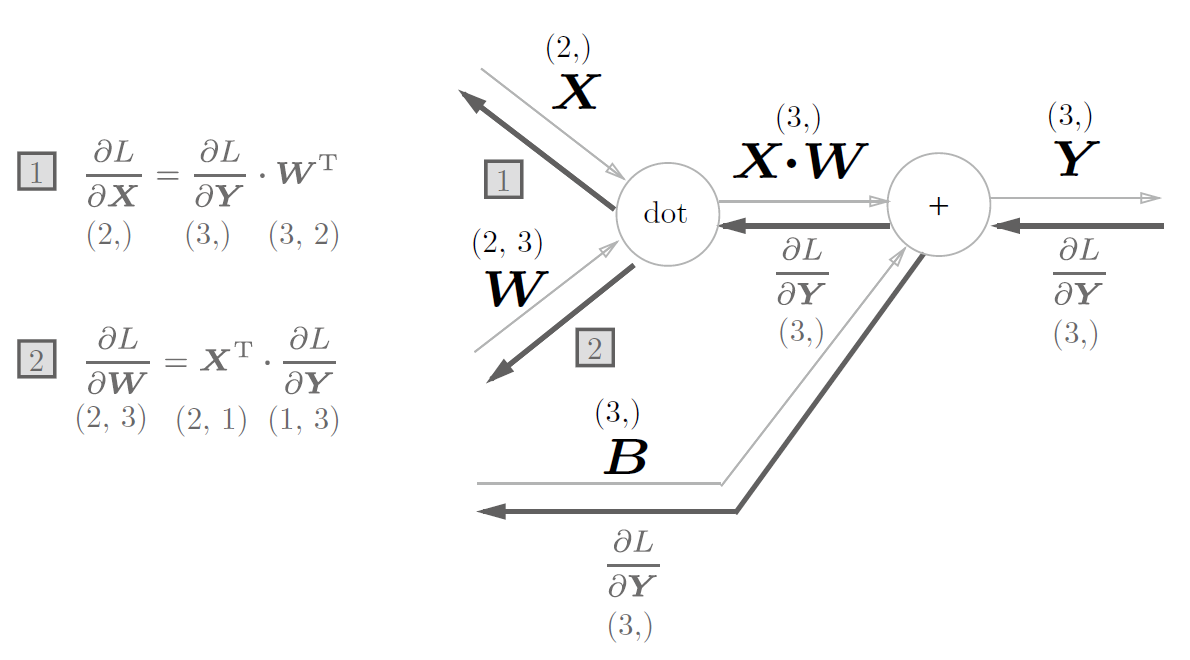
注意到$X$和$\frac{\delta L}{\delta X}$形状相同;$W$和$\frac{\delta L}{\delta W}$形状相同。
由该特性,不难推出求导结果
1.1 批版本的Affine层
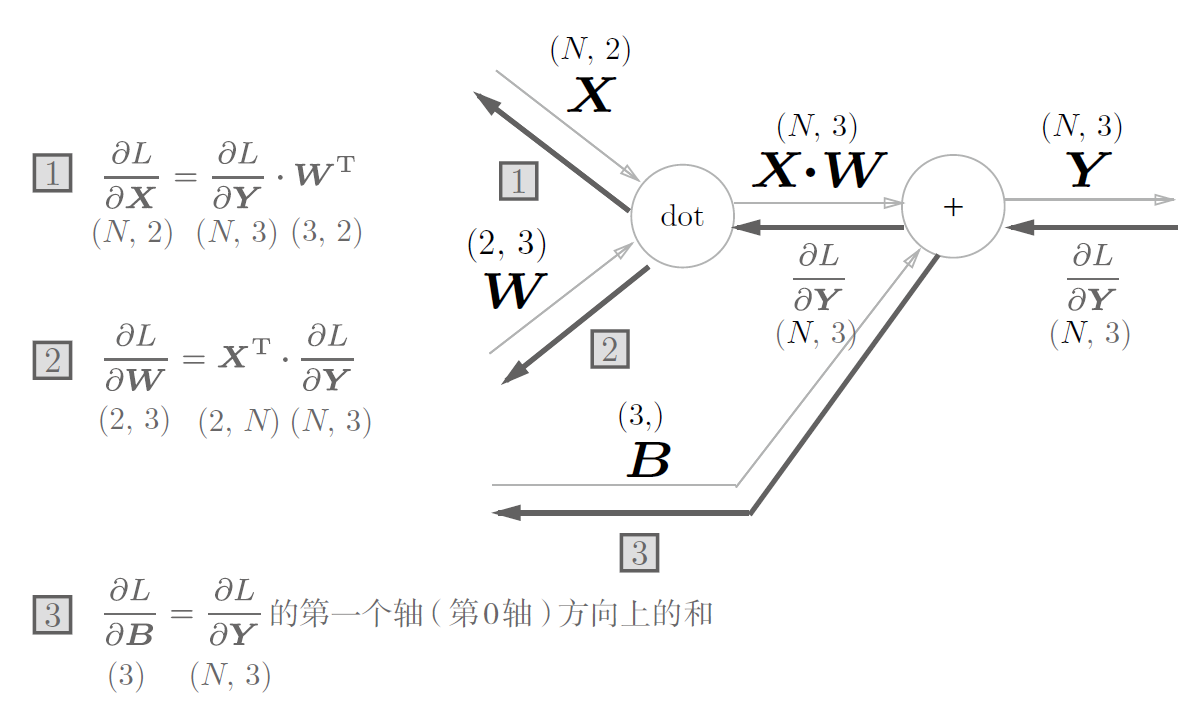
正向传播的时候,偏置会加到$X \times W$的各个数据上去,故在批版本下,会加到每一个数据里。
因此反向传播时,各个数据的反向传播值需要汇总为偏置的元素。
即
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
class Affine:
def __init__(self,W,b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self,x):
self.x = x
out = np.dot(x,self.W) + self.b
return out
def backward(self,dout):
dx = np.dot(dout,self.W.T)
self.dW = np.dot(self.x.T,dout)
self.db = np.sum(dout,axis=0)
return dx
|
2. Softmax-with-Loss 层
softmax会将输出正规化输出。在数字识别中,因为有10个数字,故其输出也有10个。
神经网络的处理有推理和学习两个阶段,推理一般不使用Softmax层。
神经网络未被正规化处理的输出结果被称为得分,当推理只需要一个答案的情况下,只对得分最大的值感兴趣,故不需要Softmax层。
神经网络的学习阶段需要Softmax层。
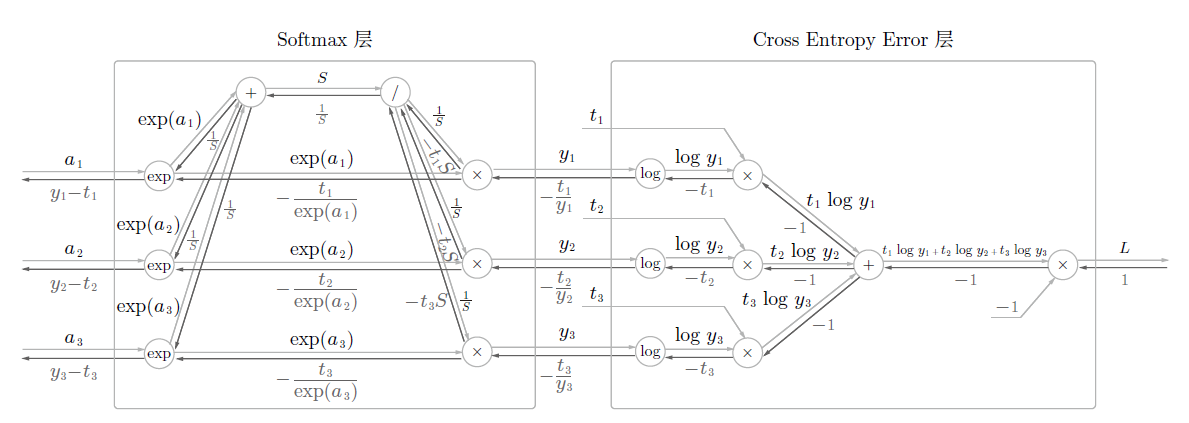
该推导较为复杂,故只看结果。
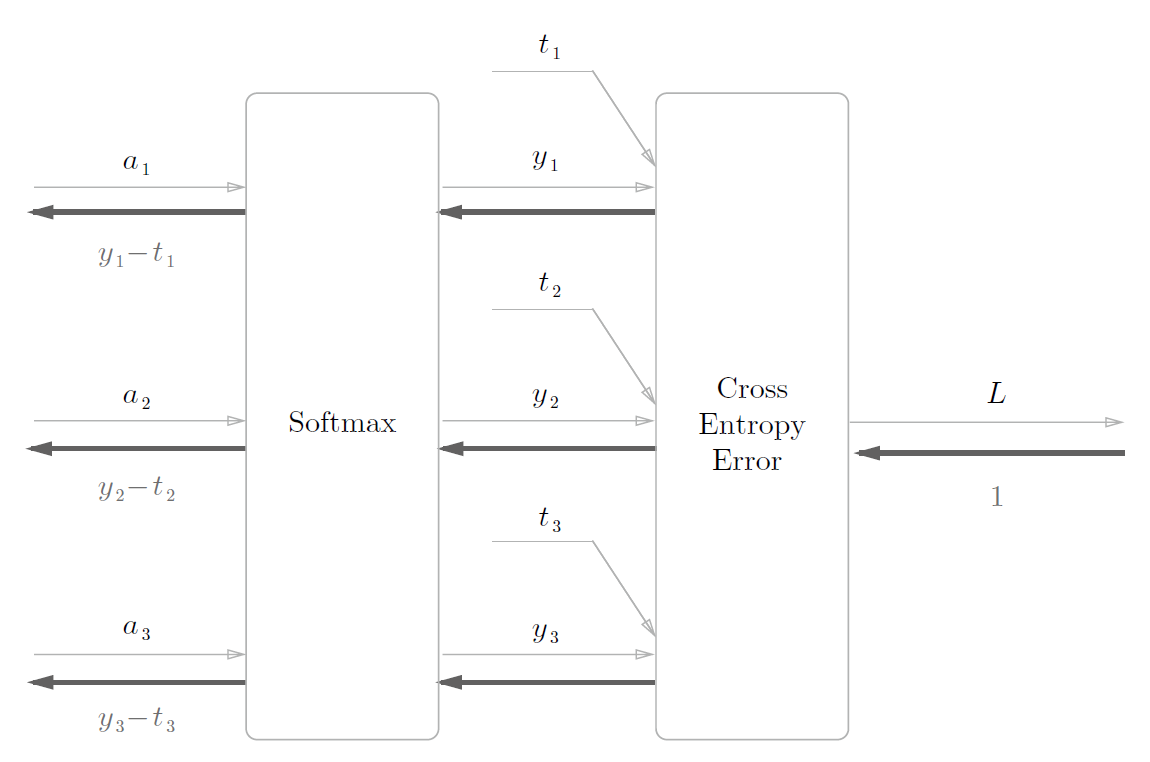
可以看到其反向传播很工整,正好是神经网络Softmax层输出与监督数据的差分。
使用交叉熵误差作为softmax函数的损失函数后,反向传播得到
(y1 − t1, y2 − t2, y3 − t3)这样“ 漂亮”的结果。实际上,这样“漂亮”
的结果并不是偶然的,而是为了得到这样的结果,特意设计了交叉
熵误差函数。回归问题中输出层使用“恒等函数”,损失函数使用
“平方和误差”,也是出于同样的理由。也就是说,使用“平
方和误差”作为“恒等函数”的损失函数,反向传播才能得到(y1 −t1, y2 − t2, y3 − t3)这样“漂亮”的结果。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
def softmax(a):
exp_a=np.exp(a)
sum_exp_a=np.sum(exp_a)
y=exp_a/sum_exp_a
return y
def cross_entropy_error(y,t):
if y.ndim == 1:
t=t.reshape(1,t.size)
y=y.reshape(1,y.size)
batch_size = y.shape[0]
return -np.sum(t*np.log(y+1e-7))/batch_size
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None
self.t = None
def forward (self,x,t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y,self.t)
return self.loss
def backward(self,dout = 1):
batch_size = self.t.shape[0]
dx = (self.y - self.t ) / batch_size
return dx
|
需要注意的是,反向传播时需要将传播的值除以批的大小后,传递给前面的层是单个数据的误差。
误差反向传播法的实现
1. 神经网络学习步骤
- 前提:
神经网络中有合适的权重和偏置,调整这些数据,以拟合训练数据的过程为学习。学习分为4个步骤
(mini-batch):从训练数据中随机选择一部分数据。
计算梯度:计算损失函数关于各个权重参数的梯度。
更新参数:将权重参数延梯度方向进行微笑的更新
重复1. 2. 3.
在步骤2会使用到误差反向传播法,比数值微分高效许多。
二层神经网络(TwoLayerNet)代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
|
import sys, os
sys.path.append(os.pardir)
import numpy as np
from source.common.layers import *
from source.common.gradient import numerical_gradient
from collections import OrderedDict
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
self.loss(x, t)
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
|
注意#++#与#--#之间的部分,采用了OrderedDict有序字典,即可以记住添加元素的顺序。
故正向传播只需要按照添加元素的顺序调用各层的forward()方法即可实现
反向传播只需按照相反的顺序调用即可。
这种以层的方式实现可以很轻松构建神经网络。
梯度确认
由于反向传播法较为复杂,容易出错,故可以采用数值微分法进行确认。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
import sys, os
sys.path.append(os.pardir)
import numpy as np
from source.dataset.mnist import load_mnist
from source.ch05.two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:3]
t_batch = t_train[:3]
grad_numerical = network.numerical_gradient(x_batch, t_batch)
grad_backprop = network.gradient(x_batch, t_batch)
for key in grad_numerical.keys():
diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) )
print(key + ":" + str(diff))
|
W1:2.7453979178765813e-10
b1:1.5954478661383414e-09
W2:4.2198711969510414e-09
b2:1.399512964808669e-07
误差很小,故结果正确。
使用反向传播法学习
因仅修改了#++#与#--# 部分,故不作解释。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
import sys, os
sys.path.append(os.pardir)
import numpy as np
from source.dataset.mnist import load_mnist
from source.ch05.two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grad = network.gradient(x_batch, t_batch)
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)
|
总结
本章介绍了计算图法的误差反向传播法。
使用计算图,可以很清晰展现计算过程
计算图的节点由局部计算构成
计算图的正向传播进行一般的计算,计算图的反向传播可以计算各个节点的导数。
通过将神经网络的组成元素实现为层,可以高效的计算梯度。
通过数值计算和误差反向传播法比较,可以确认误差反向传播是否正确。